This is a story about the decisions and compromises made in the design and build of a reliable, scalable and maintainable data-driven application, starting from raw unstructured data.
The raw data is a highly unstructured set of webpages providing the details of 371 meetings. Categories of information were identified at this stage, as well as noticing needed information is not neatly wrapped in elements. Other creative patterns need to be explored to algorithmically extract all needed information.
A database schema was conceptualized to understand what information needed to be extracted and stored, and in what manner. To keep options open, the design architecture considered: 1) the database as a collection of records, 2) each record would eventually be organized primarily by geolocation and time, and 3) the records should be in JSON document format to eventually support either nosql or sql design.
To parse the jungle of meetings from the unruly webpages, it seemed most natural to organize data by where they existed spatially (i.e. left-hand column, middle column, right column) because that was the only consistent order I immediately saw. Then the correct columns could be traversed by identifying which number they fell under (i.e. middle columns started from i=1 and exist for n+3). Content was parsed and organized by pulling all content and performing a regex search pattern for information identified in the data architecture design (see 02).
The parsed data then used the street address and zip code fields to match against a geolocation API to obtain latitudes and longitudes for each entry object.
First exhibit: The data is parsed first as nosql-friendly entries following the database schema
Second and Third exhibits: Since ultimately an RDS was used, a script was written to easily convert the JSON to sql-friendly entries (line items of individual meetings)
Fourth exhibit: The data sent to the RDS in AWS creates line items for each meeting, which can be later aggregated by geolocation and time in the application as desired by the database schema design.
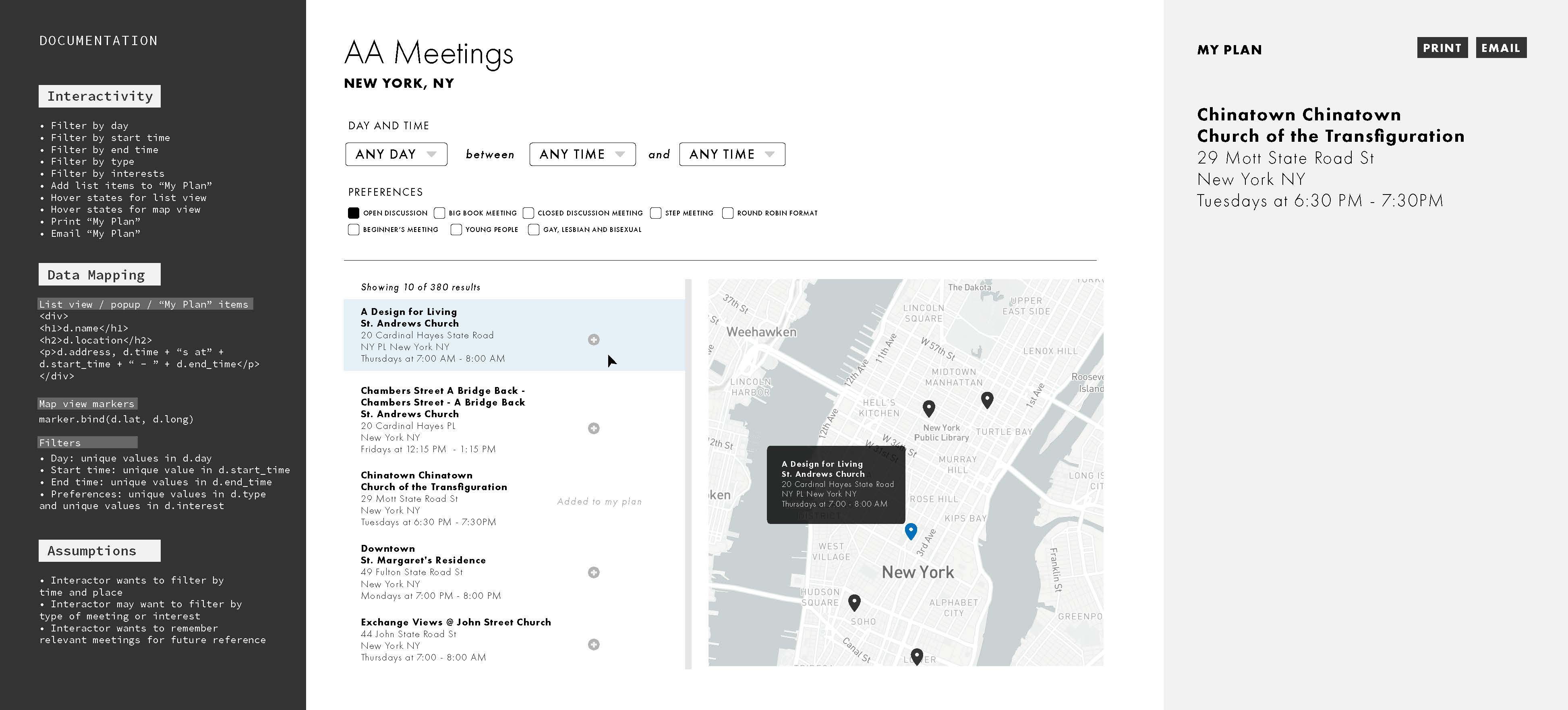
To map the data to an interface, a documentation for a test build was created to understand the minimal visual artifacts needed to satisfy gen.1 user assumptions, how those visual artifacts would be mapped to the data, and what level of interactivity is need to complete the experience. From these sepcs, the final application was built in node.js.
Data Source
![]() Tools
Tools